> x <- c(145,148,152,154,158,159,163)
> y <- c(50,52,54,56,58,60,62)
> df_1 <- data.frame(height=x,weight=y)
> df_1 height weight
1 145 50
2 148 52
3 152 54
4 154 56
5 158 58
6 159 60
7 163 62R において、方形の形をした表形式のデータ型である データフレームについて説明し、ファイルに書かれたデータを R で読み込む方法について説明する。 そして、読み込んだデータを分析の方法に応じて変形する方法について 説明する。また、データ分析のための R のパッケージ群 tidyverseについて説明する。
データフレーム、パッケージ、 ファイルの読み込み、パイプ演算子、tidyverse
行列は行と列という 2つの次元からなるが、 行列の成分は1種類の数値データである(文字列のみの行列を作ることもできる)。 異なる要素からなるデータもある。例えば、名簿のようなデータを考えると、名前は文字列、年齢であれば数値、他にも職業分類のように何種類かある 値のどれか(これをカテゴリーデータという)、 というように列ごとに異なる属性を持つ。このような行と列からなる2次元の表形式のデータ型を データフレームという。データフレームは上記のように、列ごとに異なる属性はあるが、長さの等しい ベクトルから構成される長方形の形をしたデータである。 一方、前章で計算した eigen(A) のように、固有値とベクトルという長さや構造が異なるものを 1つのまとまりとして扱うこともある。このまとまりを リストという。 データフレームを作成する場合にはdata.frame()という 関数を用いる。
> x <- c(145,148,152,154,158,159,163)
> y <- c(50,52,54,56,58,60,62)
> df_1 <- data.frame(height=x,weight=y)
> df_1 height weight
1 145 50
2 148 52
3 152 54
4 154 56
5 158 58
6 159 60
7 163 62今までは、データを一つ一つ入力することを考えた。 しかし、Webサイトからダウンロードするなど データを入手することも多いだろう。 また、自分でデータを入力する場合も、データの規模が大きい場合には、 RStudio のエディターで入力するよりも 表計算ソフトを利用する方が便利であることも多い。次にこうしたファイル読み込みについて述べる。
表計算ソフトでデータを扱う場合には、 表示の文字を修飾したり、表示桁数を制御したりすることもあるが、 実際の値と値同士を区切る具体的な値とその値をどうやって区切っているかが分かれば良い。この区切り文字を デリミタ(delimiter)という。区切り文字としては半角スペースやカンマ(,)が よく用いられる。 そして、カンマで文字を区切ったファイル形式を CSV 形式(Comma Separated Value)という。 パソコンではファイル名のピリオドの後につけられる拡張子によって、 どのアプリケーションで開くかの関連付けがされている。 CSVファイルであれば、拡張子.csv が用いられる。 R でCSVファイルを読み込むには read.csv()という関数を用いる。
> df_2 <- read.csv("data/weight.csv")ファイルを読み込むにはフォルダ read.csv()はどのファイルを読むかというファイルの在処を指定し、その後に、選択可能な追加項目(オプション)を記述する。 データの1行目が各列の説明である場合にはheader=TRUEと指定する。2章で述べたように、関数のオプションでは省略した場合にあらかじめ値が定められていることがある。read.csv()では何も指定しないと TRUEなので、省略してもよい。 関数については help(関数名) または ?関数名 とすると RStudio の右下の小窓の Help欄に説明が表示される。
> ?read.csvこのHelpのタブの検索窓に関数名を入力して探すこともできる。
Help は英語ではあるが、最後の方に例がある。 Run Example をクリックするとどのような動作になるのかを確認できる。
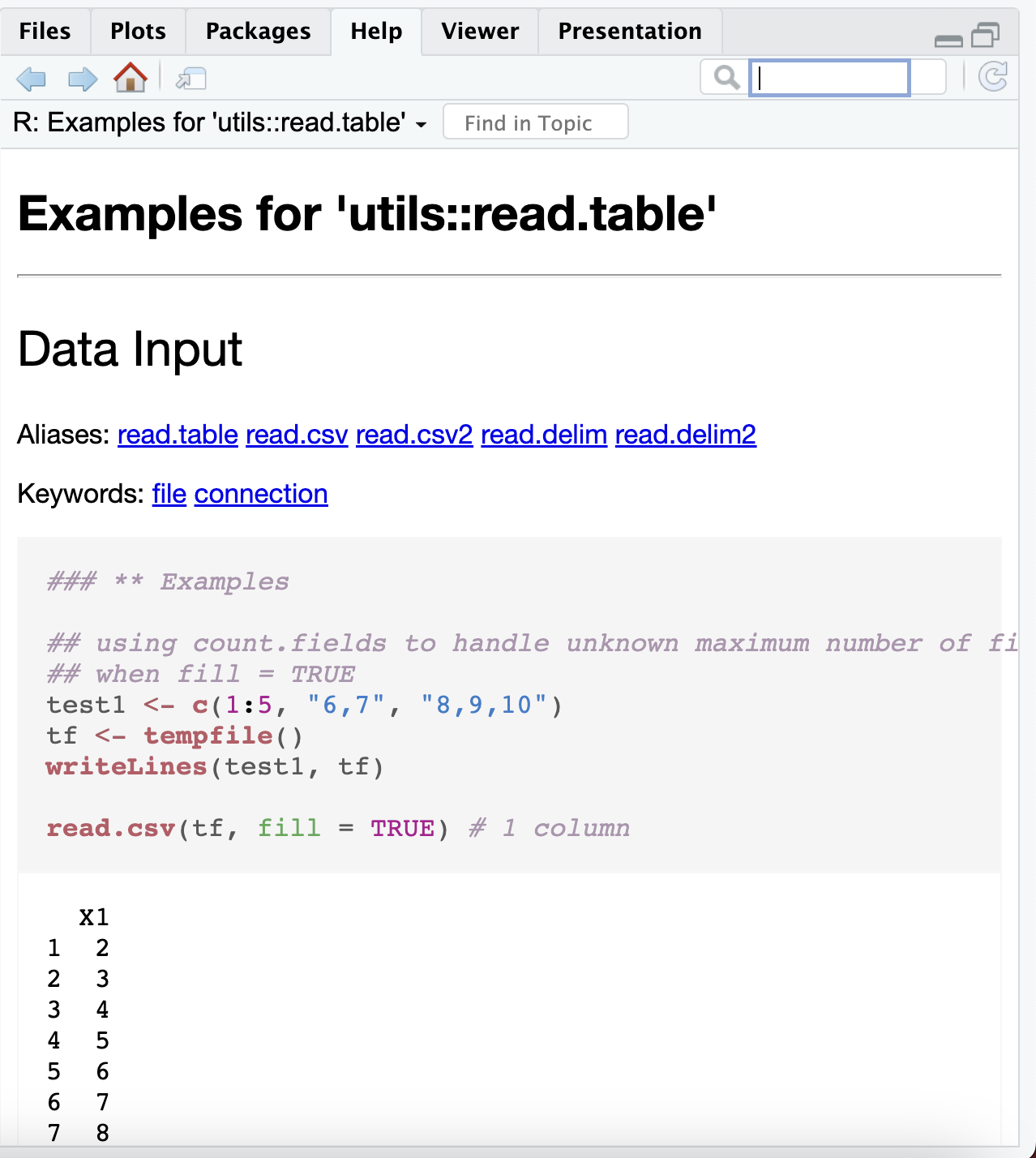
ファイルを読み込んだ結果を見てみよう。
> df_2 name1 A B
1 A1 148 52
2 A2 152 54
3 A3 154 56
4 A4 158 58
5 A5 163 60csvファイルが読み込まれ、R上 で データフレームとして h2 という名前で 読み込まれる。
これはRStudio の右上の Environment のタブでも 確認できる。
今まで利用していた関数はRをインストールした時に含まれるbaseというパッケージに含まれる関数だった。RStudio で
> library(help = "base")とするとこのパッケージに含まれる関数などの情報を見ることができる。
baseパッケージ の情報tidyverse は データサイエンスに向けた統一した考えに基づいて設計されたパッケージの集まりであり、 Hadley Wickham らが中心となって 開発されている。 インストールした後に利用するには
> library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.2 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsとする。 主なパッケージとしては、
ggplot2: データの可視化
tibble: データフレームの拡張
tidyr: データフレームの変形
readr: ファイルの読み込み
purrr: リストの並列処理
dplyr: データフーレムの処理
stringr: 文字列操作
forcats: 因子型データの操作
などがある。この他にも日付型データ操作のためのlubridate などのパッケージが含まれている。 異なるパッケージで同じ関数名が用いられることがある。 statsというパッケージにも filter()という関数があり、 dplyrというパッケージにも filter()という関数がある。 そのため、filter()とした場合には dplyr のパッケージが 用いられる。関数の前に パッケージ名::: とすると パッケージを指定して関数を利用することもできる。 tibble はデータフレームを拡張したもので 作り方はデータフレームと同じように作ることができる。
df_3 <- tibble(height=x,weight=y)
df_3# A tibble: 7 × 2
height weight
<dbl> <dbl>
1 145 50
2 148 52
3 152 54
4 154 56
5 158 58
6 159 60
7 163 62表示されたものを見ると、データフレームは変数名を指定すると全ての行が表示されるが、tibble は デフォルトでは10行までしか表示されない。各列にその列の型名が表示される。そして、tibble にはtibble 自体を要素とすることもできるなどの違いがある。 ファイルの読み込む関数として、read.csv の改良版にあたるものが readr という パッケージに含まれている read_csv という関数である。
> df_4 <- read_csv("data/weight.csv")
> df_4# A tibble: 5 × 3
name1 A B
<chr> <dbl> <dbl>
1 A1 148 52
2 A2 152 54
3 A3 154 56
4 A4 158 58
5 A5 163 60日本語を含むファイルの場合、文字コードが違うと文字化けすることがある。 read_csv()では locale=locale(encoding="文字コード名") と指定する。 ファイルは tibble 形式で読み込まれる。
> df_4# A tibble: 5 × 3
name1 A B
<chr> <dbl> <dbl>
1 A1 148 52
2 A2 152 54
3 A3 154 56
4 A4 158 58
5 A5 163 60tidyverse のパッケージ tibble read_csv や as_tibble などbase のパッケージと 類似の関数名ではあるが、baseが ピリオドで区切られている ものに対して、 _ で区切られている。
この教材では今後、分析対象のデータは データフレーム形式を想定し、様々な変形を行う。 dplyr はデータ操作のための パッケージである。
dplyr の主な関数 |
説明および例 |
|---|---|
filter |
要件を満たす行の抽出 |
select |
列の選択 |
mutate |
新しい列を作る |
arrange |
列の並べ替え |
summrise |
データの要約 |
例えば、先ほど作成した身長はcmの 単位だったので、mで表したければ
> df_3 <- mutate(df_3,height= height/100)
> df_3# A tibble: 7 × 2
height weight
<dbl> <dbl>
1 1.45 50
2 1.48 52
3 1.52 54
4 1.54 56
5 1.58 58
6 1.59 60
7 1.63 62とすると身長をm単位に直せる。 この例では 前に作った df_3を関数の引数として与え、できた結果を df_3に代入している。それによって、df_3 を 変形しているが、新たに列を作ることができる。 Rではベクトルに対して、*、/ といった演算子を使うと成分ごとの計算を行う。次の例では身長と体重の列から
> df_3 <- mutate(df_3,BMI = weight/ height^2)としてBMIという列を追加している。
この2つの例のように、df_3を出発点に色々と変形を繰り返していくことがある。 このようなときに便利なのが、パイプ演算子 である。 R には baseパッケージに |>、また、 tidyr というパッケージに %>% という演算子がある。 パイプ演算子は、xを関数fに入力するときにf(x) とする代わりに、x %>% f()と書くことで計算ができる。 f(x,y)の場合には x %>% f(y) と書くことができる。 それを使うと、先ほどの計算は
> df_3 <- tibble(height=x,weight=y)
> df_3 <- df_3 %>%
+ mutate(height = height / 100) %>%
+ mutate(BMI = weight/height^2 )
> df_3# A tibble: 7 × 3
height weight BMI
<dbl> <dbl> <dbl>
1 1.45 50 23.8
2 1.48 52 23.7
3 1.52 54 23.4
4 1.54 56 23.6
5 1.58 58 23.2
6 1.59 60 23.7
7 1.63 62 23.3と書くことができる。 tidyverse とは別に magrittr というパッケージをインストールすると この代入の作業を含めた %<>% という演算子を使うことができる。
> library(magrittr)
> df_3 <- tibble(height=x,weight=y)
> df_3 %<>% mutate(height = height / 100) %>%
+ mutate(BMI = weight/height^2 )と書くことができる。ここで、R では行ごとに命令が完結していると命令が終わったものと判断される。 また、入力が長いと読みにくくなるため、 パイプ演算子を使うときには %>% としてから改行する。
データによっては複数のデータフレームを結合するという 場合もある。次の例は同じ id を持つ100人の学生が異なる3つの試験を 受けた結果が入っている。inner_join(x,y) とすると x とy で同じ列名を持つ列の値を比較して結びつける。 inner_join の場合には x と y の両方に共通するものだけを 結合する。left_join(x,y)は x にあるidに対応する idのyの科目の点数を結びつけて 列を追加する。right_join(x,y)はyにあるidに対応するxの科目の点数を結びつけて 列を追加する。full_join(x,y)はどちらか一方にだけ含まれているidの科目を結びつけて列を追加する。inner_join` 以外の場合に対応する値がない場合には欠損値 を表す NA として結びつけるx。
> df_suba <-read_csv("data/subA.csv")
> df_subb <-read_csv("data/subB.csv")
> df_subc <-read_csv("data/subC.csv")
> df_sub <- df_suba %>%
+ inner_join(df_subb) %>%
+ inner_join(df_subc)
> df_sub %>% head()# A tibble: 6 × 4
id subA subB subC
<dbl> <dbl> <dbl> <dbl>
1 1 38 43 81
2 2 53 61 33
3 3 42 41 39
4 4 49 54 54
5 5 37 57 63
6 6 39 39 52このようにして得られた df_sub は科目ごとに別の列となっている。 次の章で示す箱ひげ図を書くという場合 には、 subA、subB、subCの結果を subject として1つの列にまとめたい ということもある。 tidyrというパッケージにある pivot_longer という 関数を用いると複数の列を1つにまとめて 長い列を作成することができる。 まとめたい列を指定し、それによってできる 新しい列名をnames_to、値を表す列名 をvalues_to で指定する。 write_csvで変数をCSVファイルに書き出すことができる。
> df_longsub <- df_sub %>%
+ pivot_longer(c(subA,subB,subC),
+ names_to="subject",
+ values_to="score")
> df_longsub %>% head()# A tibble: 6 × 3
id subject score
<dbl> <chr> <dbl>
1 1 subA 38
2 1 subB 43
3 1 subC 81
4 2 subA 53
5 2 subB 61
6 2 subC 33> write_csv(df_longsub,"data/long.csv")表示は6行だが、実際には300行ある。 一方で、このように長いデータを列の値に応じて横に広い形に 変形するには pivot_wider()を 用いる。
> df_widesub <- df_longsub %>%
+ pivot_wider(names_from="subject",
+ values_from="score")
> df_widesub %>% head()# A tibble: 6 × 4
id subA subB subC
<dbl> <dbl> <dbl> <dbl>
1 1 38 43 81
2 2 53 61 33
3 3 42 41 39
4 4 49 54 54
5 5 37 57 63
6 6 39 39 52> write_csv(df_widesub,"data/wide.csv")もう一度広げることで df_widesubは df_sub と一致している。
特定の列を抽出するには select()、ある条件を満たす行を抽出するには filter という関数がある。
> iris %>% select(Species) %>% table()Species
setosa versicolor virginica
50 50 50 > iris %>% filter(Species=="setosa") %>% head() Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosatidyverse については詳しく知るには Haley Wickham の本がある(参考文献[2])。英語であれば 最新のものをWeb (参考文献[1])で見ることもできる。 ただし、開発中のため同じ環境を整備するのは 難しい。 また、日本語でも多くの本が出版されており、[3] などがある。
[1]. Hadley Wickham, “Tidy Data” Journal of Statistical Software, vol.59(10), pp1–23,2014 https://www.jstatsoft.org/index.php/jss/article/view/v059i10
[2]. Hadley Wickham,Garrett Grolemund(著),黒川利明(訳) “Rではじめるデータサイエンス”,オライリー・ジャパン,2017, https://r4ds.had.co.nz/
[3]. 松村優哉,湯谷啓明,紀ノ定保礼,前田, 和寛, “改訂2版 RユーザのためのRStudio[実践]入門 :tidyverseによるモダンな分析フローの世界”, 技術評論社,2021,
Cheat sheets とある。ここで、関数やソフトウェアの操作について イラストなどで説明したチートシート(早見表) を見ることができる。
また、Posit社のWebサイトには有志によって各国の言語に翻訳されたものもある。
tibble を作成して mutate、select、filter などの動作を確認してみよ。