4 データの視覚化
データの持つ特徴を視覚的に表現する方法がグラフである。 R ではグラフの種類に違いがあっても共通の文法に則って書くことが できるように設計された ggplot2 というパッケージがある。 散布図、棒グラフ、ヒストグラム、箱ひげ図、円グラフといった 代表的なグラフを作成する方法について説明する。
キーワード
散布図、ヒストグラム、箱ひげ図、棒グラフ、円グラフ、グラフィック文法
4.1 散布図(scatter plot)
散布図とはデータの 2つの要素を縦軸横軸上の点として表したものである。 例えば身長と体重(\(148\),\(52\))を 横軸に\(x=148\)、縦軸に\(y=52\)としてグラフ上の点に表したものである。 散布図を書くにはplot()という関数を用いる。 plot(c(\(x_1\),\(y_1\)),c(\(x_2\),\(y_2\))とすると 点(\(x_1\),\(y_1\))、(\(x_2\),\(y_2\))の点を描画する。
| 氏名 | 身長 | 体重 |
|---|---|---|
| A01 | 148 | 52 |
| A02 | 152 | 54 |
| A03 | 154 | 56 |
| A04 | 158 | 58 |
| A05 | 163 | 60 |
> h1 <- read.csv("data/weight.csv")
> plot(h1[,2:3],pch=16)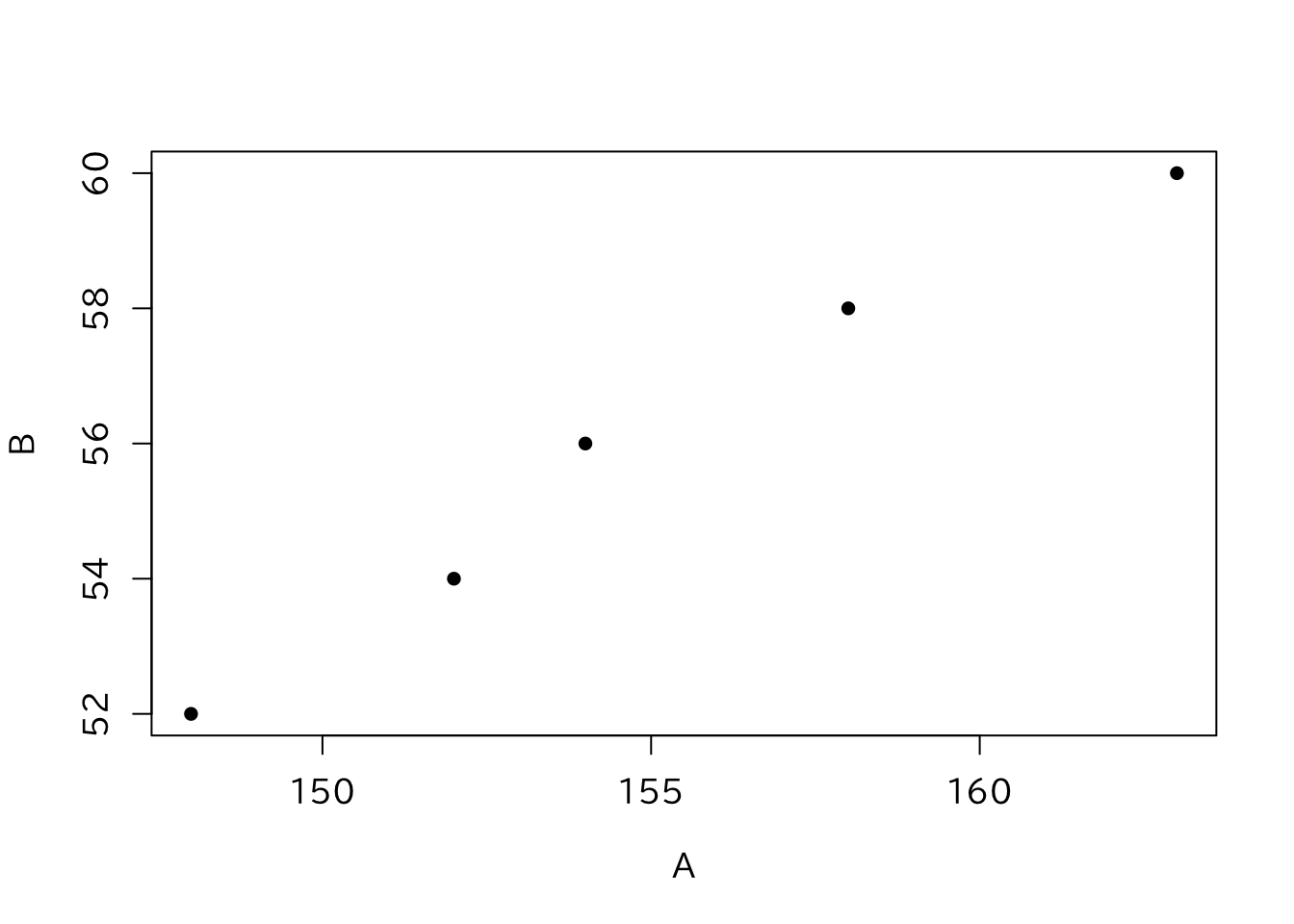
plot() は多くのオプションを指定することができる。 例えば点の種類を指定する場合、何も指定しないと各点は白い点(pch=1) としてプロットされる。一方、pch=16とすると白丸を黒く塗りつぶした点でプロットする。このように指定した番号によって三角形や×印などで表される。 また、plot()という関数は1つのコマンドで新たな図を作成するが、 その後、新たに点や線を付け加えたグラフを作成したいこともある。 この場合には追加で関数を用いる。このplot()のように新たに図を作成する ことができる作図関数を高水準作図関数といい、 作成された図に付け加えるための関数を低水準作図関数という。 例えば、points()、lines()、text()という関数は 作成した図にそれぞれ点、線、文字を追加するものである。 低水準作図関数は高水準作図関数とセットで利用し、単体ではグラフを作成することができない。 次の例は、まずplot()という関数において、 type="n"で実際には点をプロットせずに枠だけを描画し、次に textでh1の各座標に、h1の行の名前rownames(h1)をプロットしている。
> plot(h1[,2:3],type="n")
> text(h1[,2:3],h1[,1])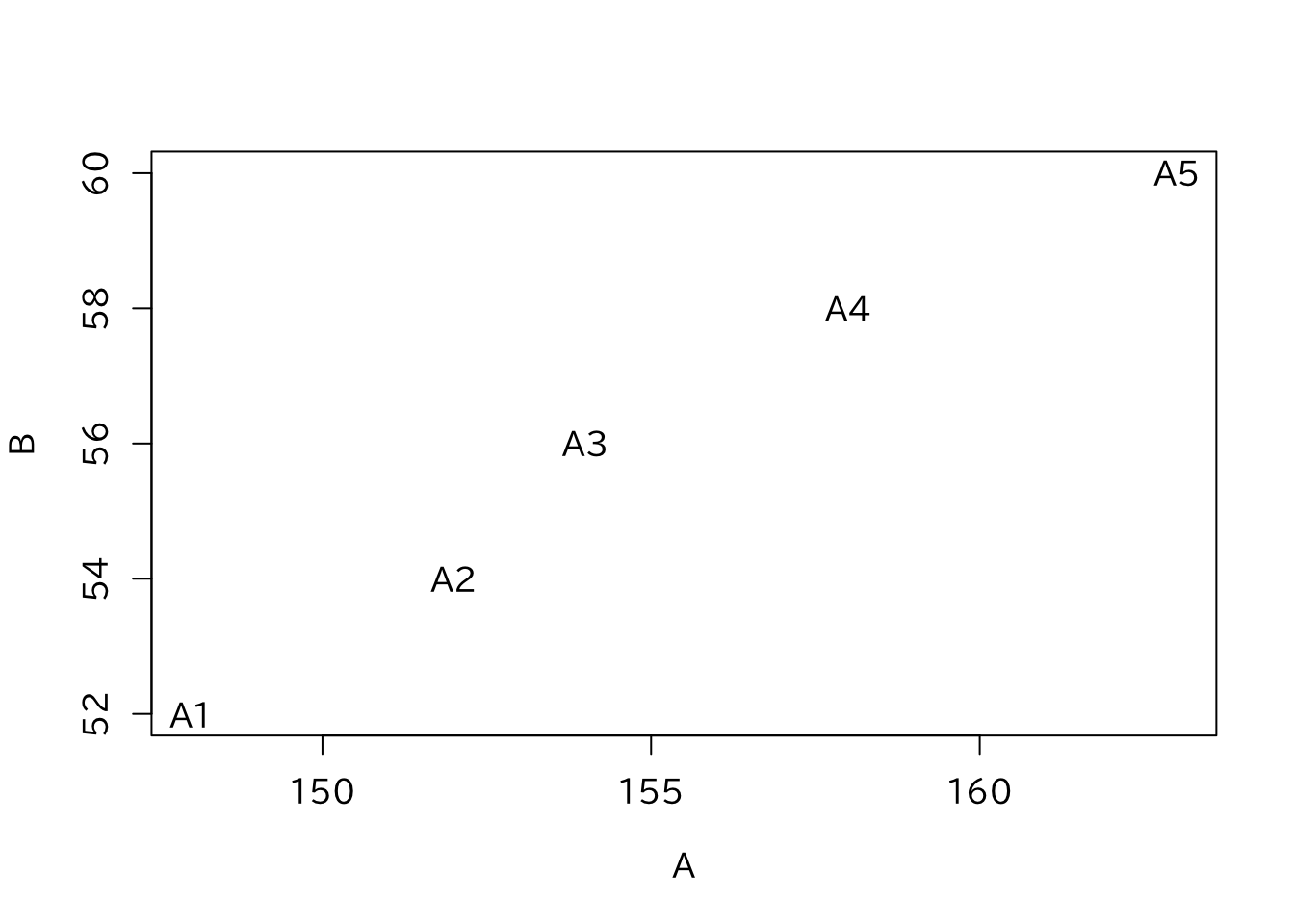
この図以外にも、複数の種類の点や線が混じっている場合には、 点や線が何を示しているかが知りたいことがある。図の中で点や線が示すものについての説明を凡例(legend)という。凡例の他に、 図を作成する場合には、後から見て何のグラフかがわかるように以下の項目が記載されているかを確認する。
凡例
軸の値
軸のラベル(軸が何を示しているか)
図の見出し(タイトル)
ただし、作成した図を使ってレポートを書く場合は、 この印刷教材のように、図の見出しの代わりにキャプションとして説明を 書く場合もある。意図的に凡例を指定する場合には、次のように指定する。
> plot(h1[,2:3],main="plot()",xlab="height",ylab="weight")
> legend(160,53,legend="e01.dat",pch=1)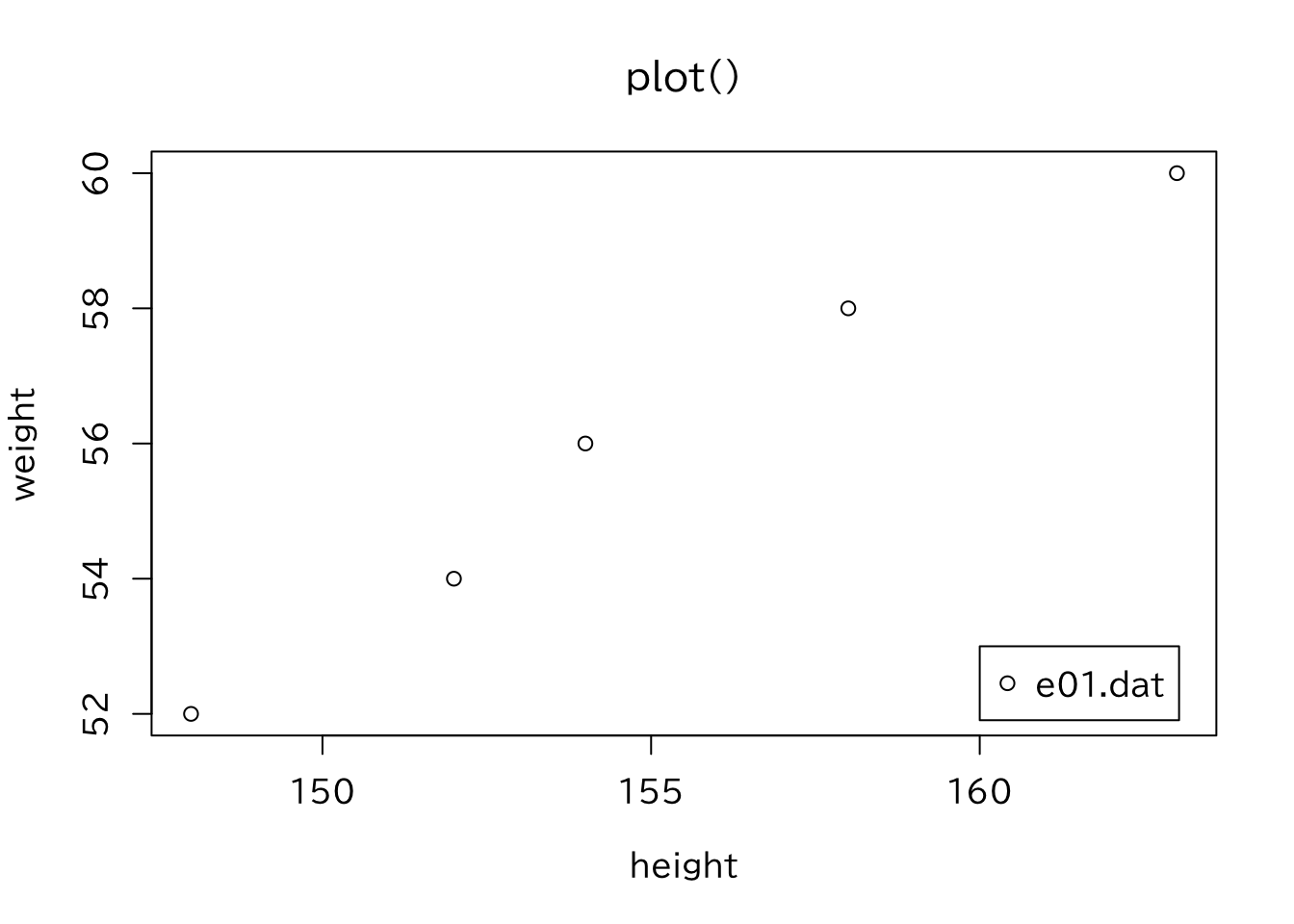
ここで、mainが図のタイトル、xlab、ylabはそれぞれ. \(x\)軸、\(y\)軸のラベルである。 凡例はlegendという低水準作図関数を用いて描画する。上の例は、 \(x=160\)、\(y=53\)の所に、点のタイプpch=1は "e01.dat"のデータであるということを示すために書いている。 R の関数は引数の値に応じて振る舞いを変える 多態性という特徴がある。 散布図を書くには plot()という関数があるが、plot() も引数の値によっては異なる振る舞いをする。
tidyverse のパッケージには、異なる種類のグラフで あっても共通の文法に基づいて描画できるように設計された ggplot2 という関数が用意されている。 ggplot2 ではまずどのデータを用いるのか、 data としてデータフレームを指定する。 aes属性でこのデータフレームのどの列がx座標 やy座標 になるのかを指定する。これによって、点や線のない空のグラフができる。 その後この座標に、様々な種類のグラフを描画していく。線や点などは+geom_()で指定する。 座標というレイヤーに+をつけて点だけのレイヤーを重ね、 さらにその上に線を書いたレイヤーを順に重ねていきグラフを作成する。 こうしてグラフを作って、最後にデザインや座標軸などの設定をしていく。 例として散布図は次のように書くことができる。geom_でdataを指定することもできるが、省略した場合にはggplotで指定したdata`であると判断する。
> ggplot(data=h1, aes(x = A, y = B,label=name1) ) +
+ geom_text()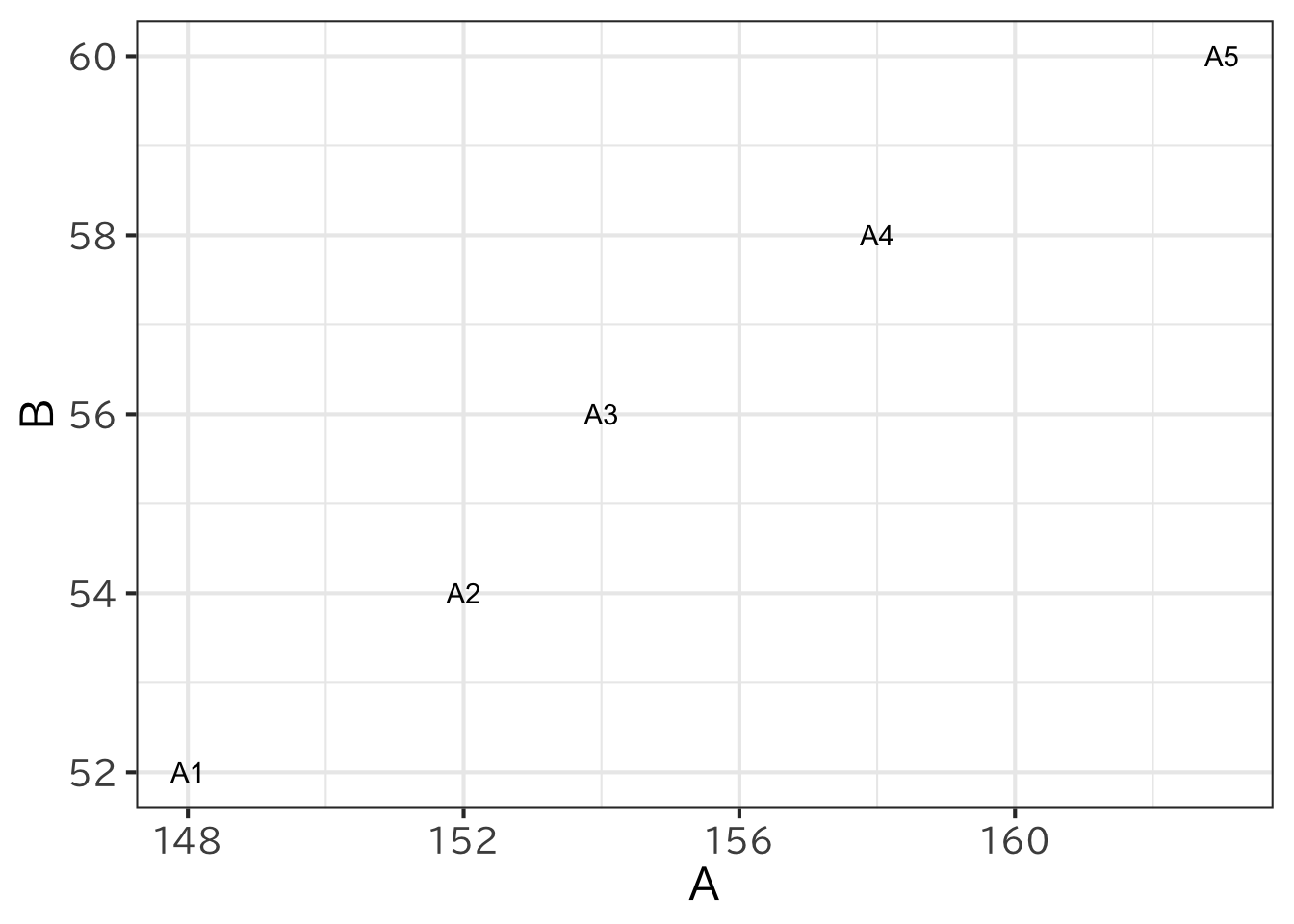
ggplot()で指定した属性が次にも引き継がれるが、以下のように書くことができる。比較する場合などはそもそも同じデータフレームになるように データフレームを整えるのも方法の一つだが、サイズの異なる別のデータフレームのデータを描画するときにはこうした方法もある。
> ggplot() +
+ geom_text(data=h1,aes(x = A, y = B,label=name1) )4.2 ヒストグラム(histogram)
データの数が多い場合に、データをある階級に分けて、その階級ごとに数を集計することがある。このとき、この階級ごとの個数を 度数(frequency)といい、全体の中で占める割合を相対度数 (relative frequency)という。区間ごとの度数の蓄積を累積度数 (cumulative frequency)、相対度数の蓄積を 累積相対度数 (cumulative relativefrequency)という。 また、階級ごとの度数(相対度数)を表す表のことを 度数分布(frequency distribution)という。 度数分布を棒グラフで表したものが ヒストグラムである。 Rでは、hist(データ)とすると、自動的に度数分布を作成し、グラフを作成してくれる。例えば、 Chapter 3 で変形した科目データを使うことにする。
> h2 <- read_csv("data/wide.csv")
> hist(h2$subA)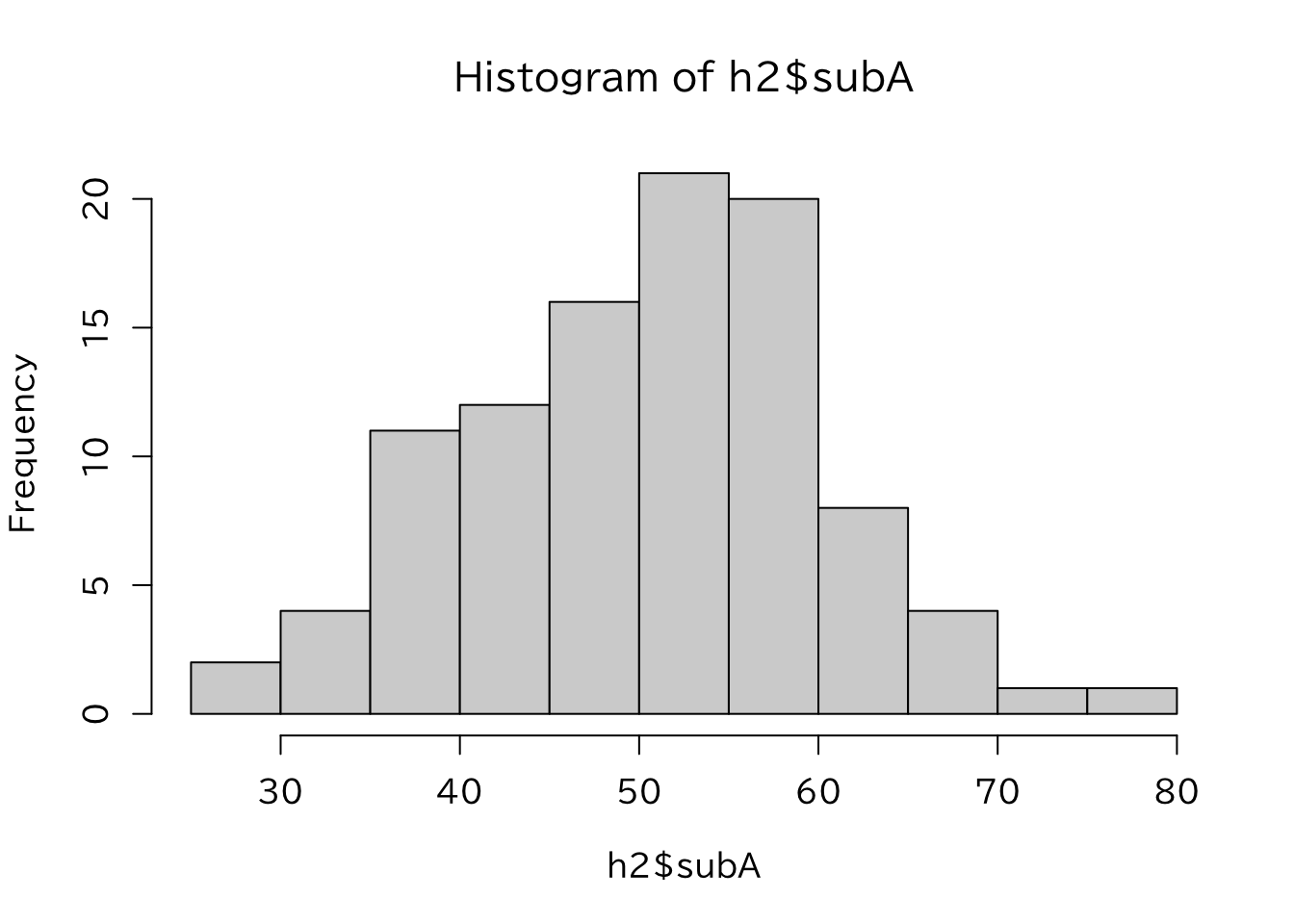
とすれば、図のようなグラフを作成してくれる。縦軸のFrequencyは度数を表している。これを割合に変える場合にはfreq=Fを加える。このようにヒストグラムは平均や分散だけではわからないデータの分布という特徴を表す。 ヒストグラムでは階級(ビンとも言う) の数をどうするかが問題になる。目安として スタージェスの公式 \(1+\log(2n)\) がある。 また、ggplot では次のように指定する
> ggplot(h2)+geom_histogram(aes(x=subA),bins=10)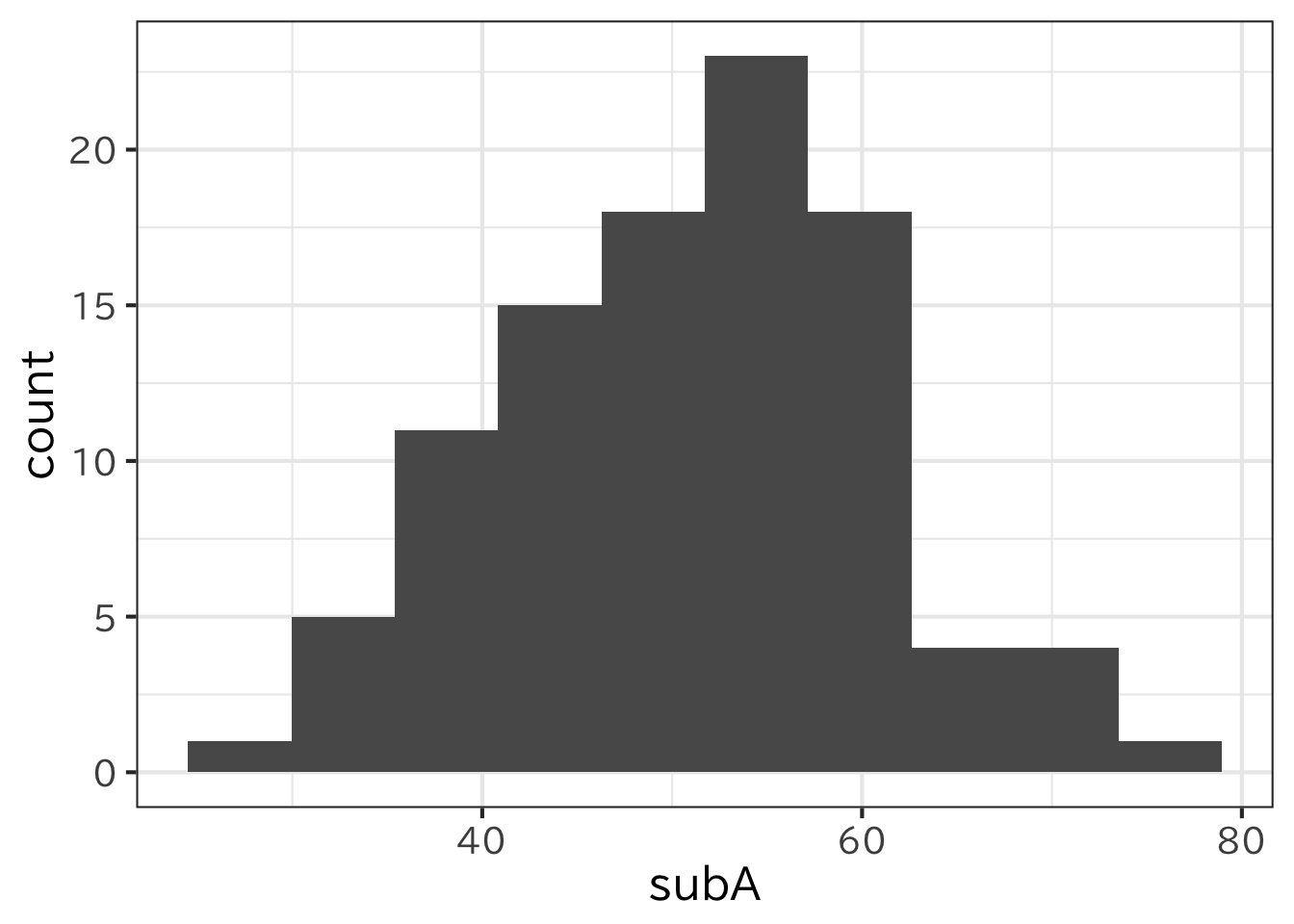
binsは階級の数)4.3 箱ひげ図
データの分布を表すもう一つの方法に箱ひげ図がある。これは データを大きい順にならべて、4等分した時の値を 図にしたもので、小さい順に、第一四分位数、第二四分位数(中央値) 、第二第三四分位数という。 箱ひげ図は複数の値がある場合にそれぞれ計算して書いてくれる。 列が分かれている場合には、Chapter 3 で行ったように pivot_longer()で 長くする。
> h3 <- read_csv("data/long.csv")
> ggplot(h3)+geom_boxplot(aes(x=subject,y=score))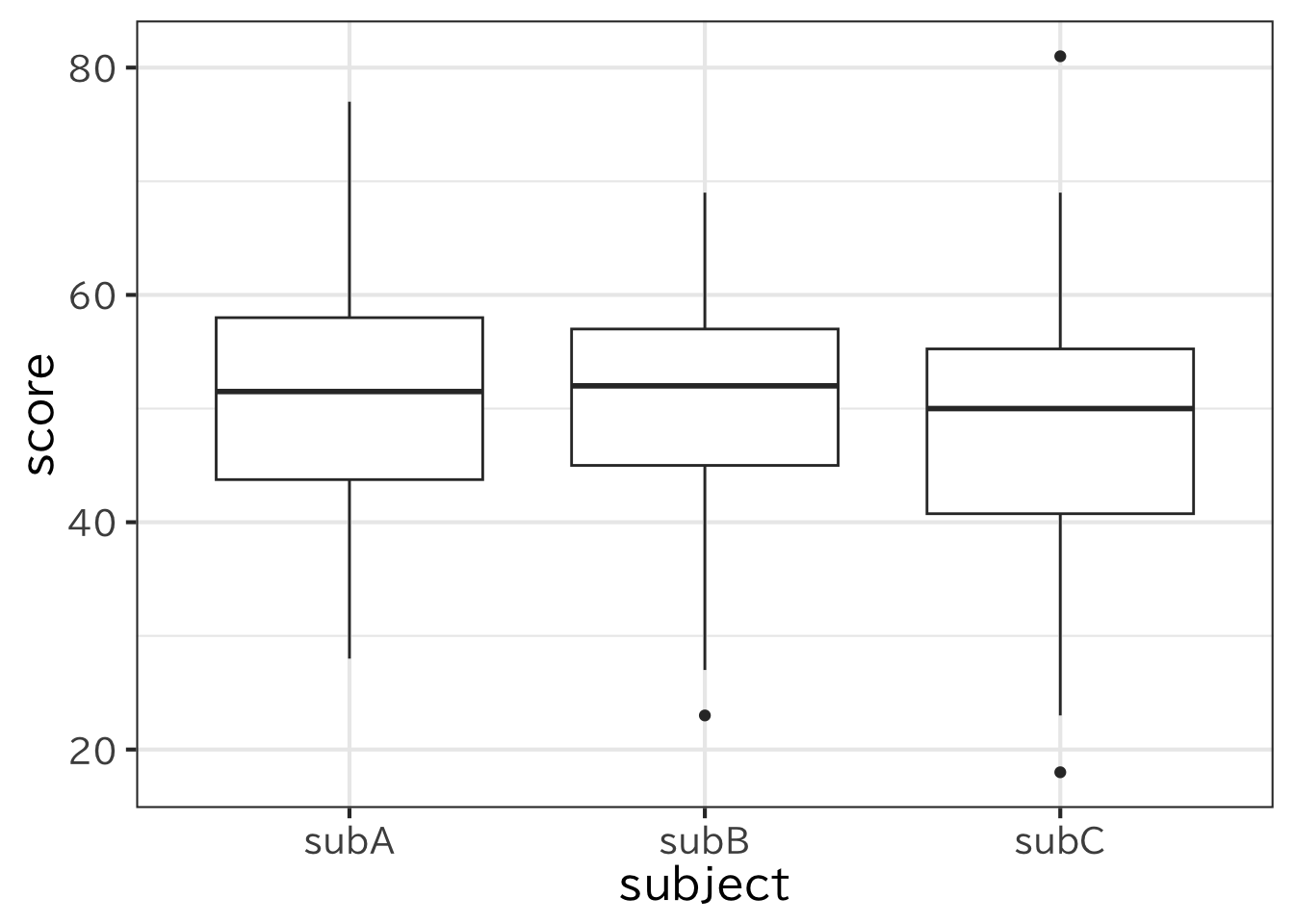
4.4 棒グラフ
棒グラフ (bar chart) は棒の長さによって値の大きさを表すグラフである。項目ごとの値を比較したいという場合に用いる。Rで棒グラフを書く場合にはgeom_bar()を用いる。 geom_bar は x のみ指定すると、 その 列にある要素をそれぞれ数え上げて棒グラフを作成してくれる。 先ほどの h3 では3科目が100個ずつあったので 次のような形になる。
ggplot(h3)+
geom_bar(aes(x=subject) ) +
scale_fill_brewer(palette = "Greys") 
あらかじめ数え上げられているデータを描画する場合には stat で "identitiy" と指定する。
c1 <- read_csv("data/freq.csv")
ggplot(c1)+
geom_bar(aes(x=name,y=freq,fill=name),stat="identity")+
scale_fill_brewer(palette = "Greys") 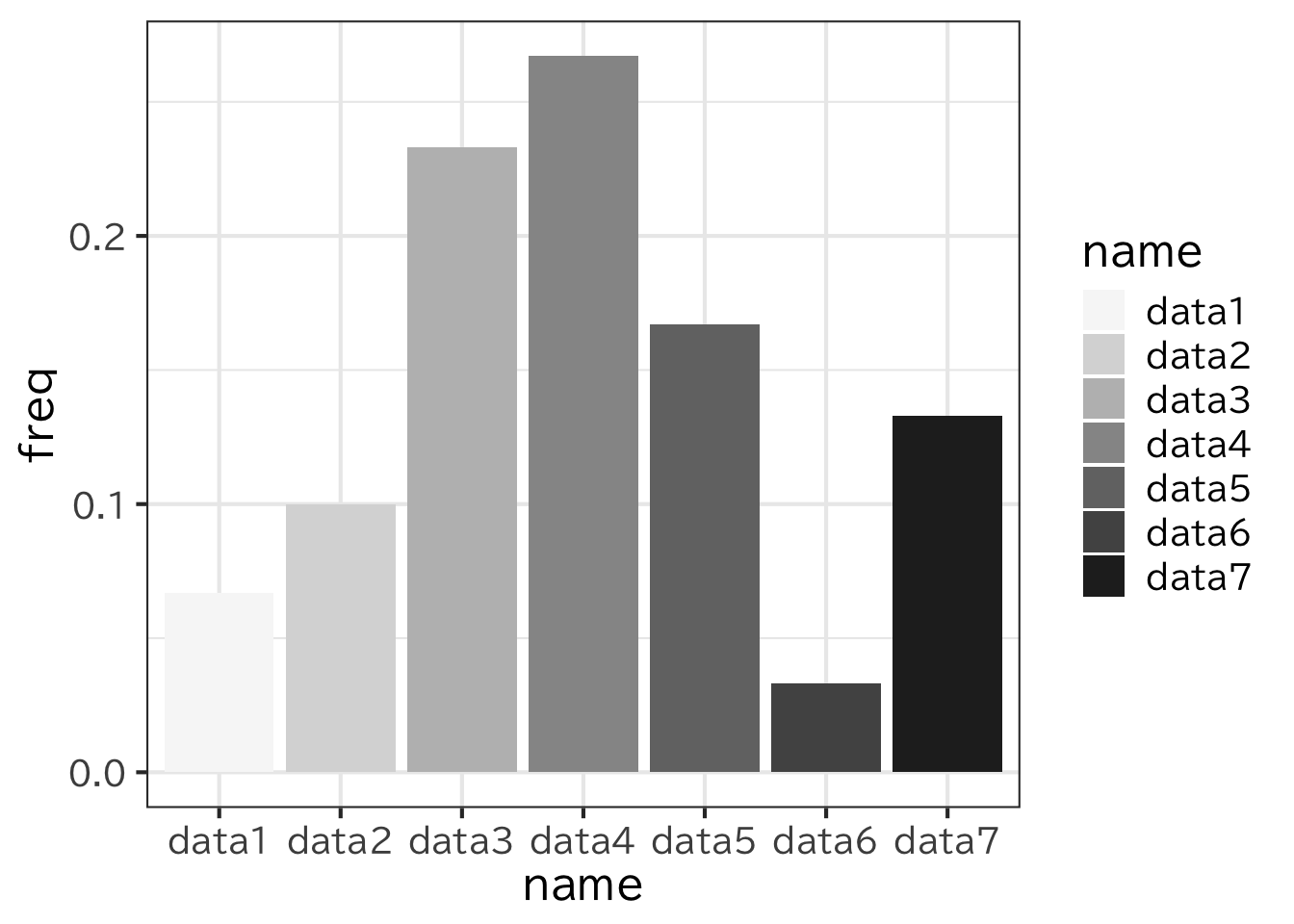
積み上げ棒グラフとは同じグループごとにまとめた 棒グラフである。
c2 <- tibble(
group = c("A","A","B","B"),
name = c("A1","A2","B1","B2"),
value=c(1,4,3,5)
)
ggplot(c2)+
geom_bar(aes(x=group,y=value,fill=name),stat="identity")+
scale_fill_brewer(palette = "Greys") 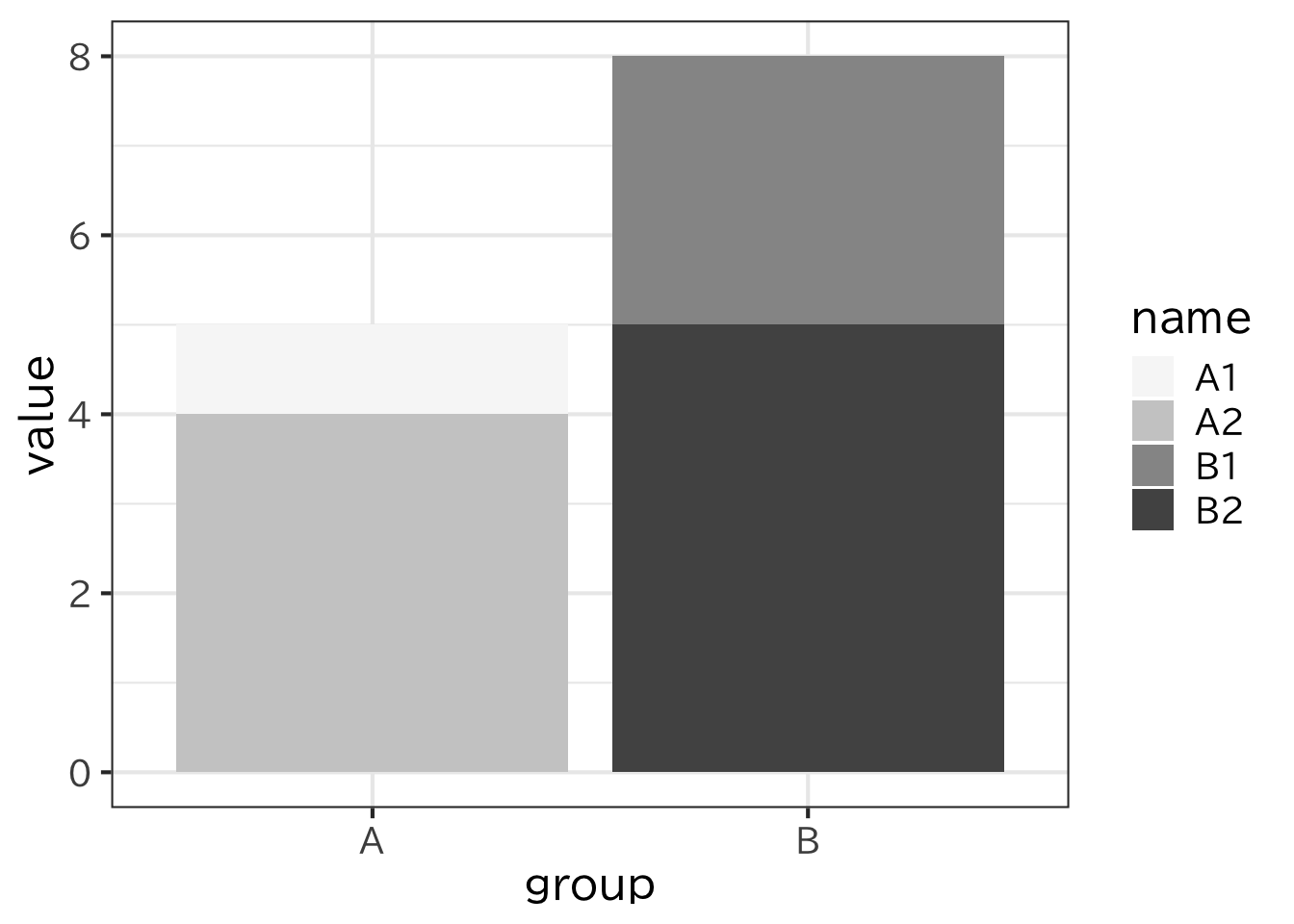
4.5 円グラフ(circle graph)
先ほどの積み上げ棒グラフを利用すると 1列の積み上げ棒グラフができる。 position=‘fill’ は縦軸の長さを揃え、それぞれの割合を表示する。
> c1 <- read_csv("data/freq.csv")
> ggplot(c1)+
+ geom_bar(aes(x="",y=freq,fill=name),
+ stat='identity',position='fill')+
+ scale_fill_brewer(palette = "Greys") 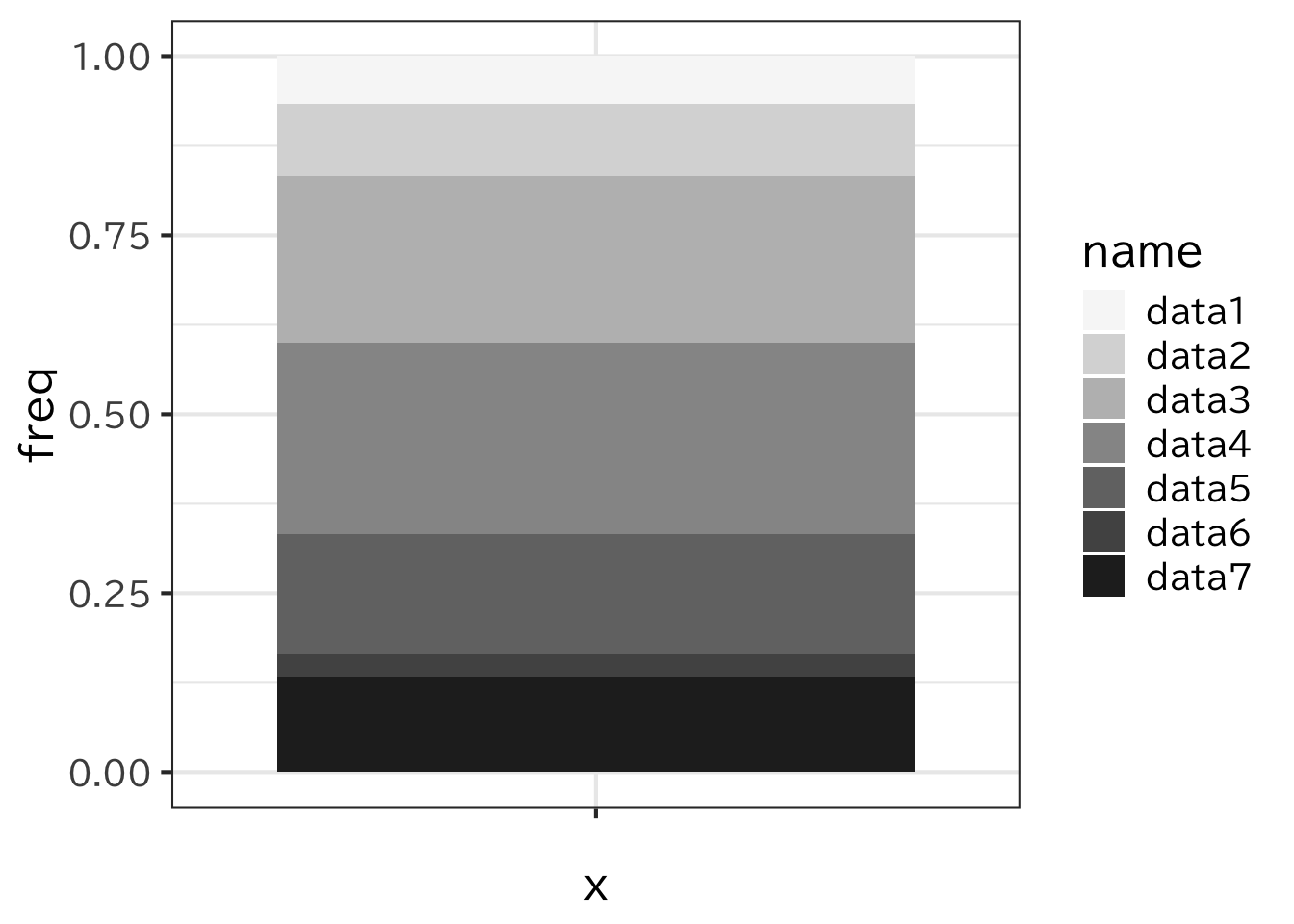
円グラフとは、全体の面積を100 (あるいは 1) として、各項目の表す割合を面積で表したものである。 次に述べるような棒グラフと同じようにデータを面積で表したものであるが、特に全体の割合を示す場合に使われることが多い。 円であると、100%であれば360度になるので、 10%であれば36度といったように割合に応じて中心の角度を定めて描画する。 円グラフは先ほど書いた積み上げ棒グラフを coord_polar で極座標表示にするとできる。
> ggplot(c1)+
+ geom_bar(aes(x="",y=freq,fill=name),
+ stat="identity",position="fill")+
+ coord_polar("y", direction=-1) +
+ scale_fill_brewer(palette = "Greys") 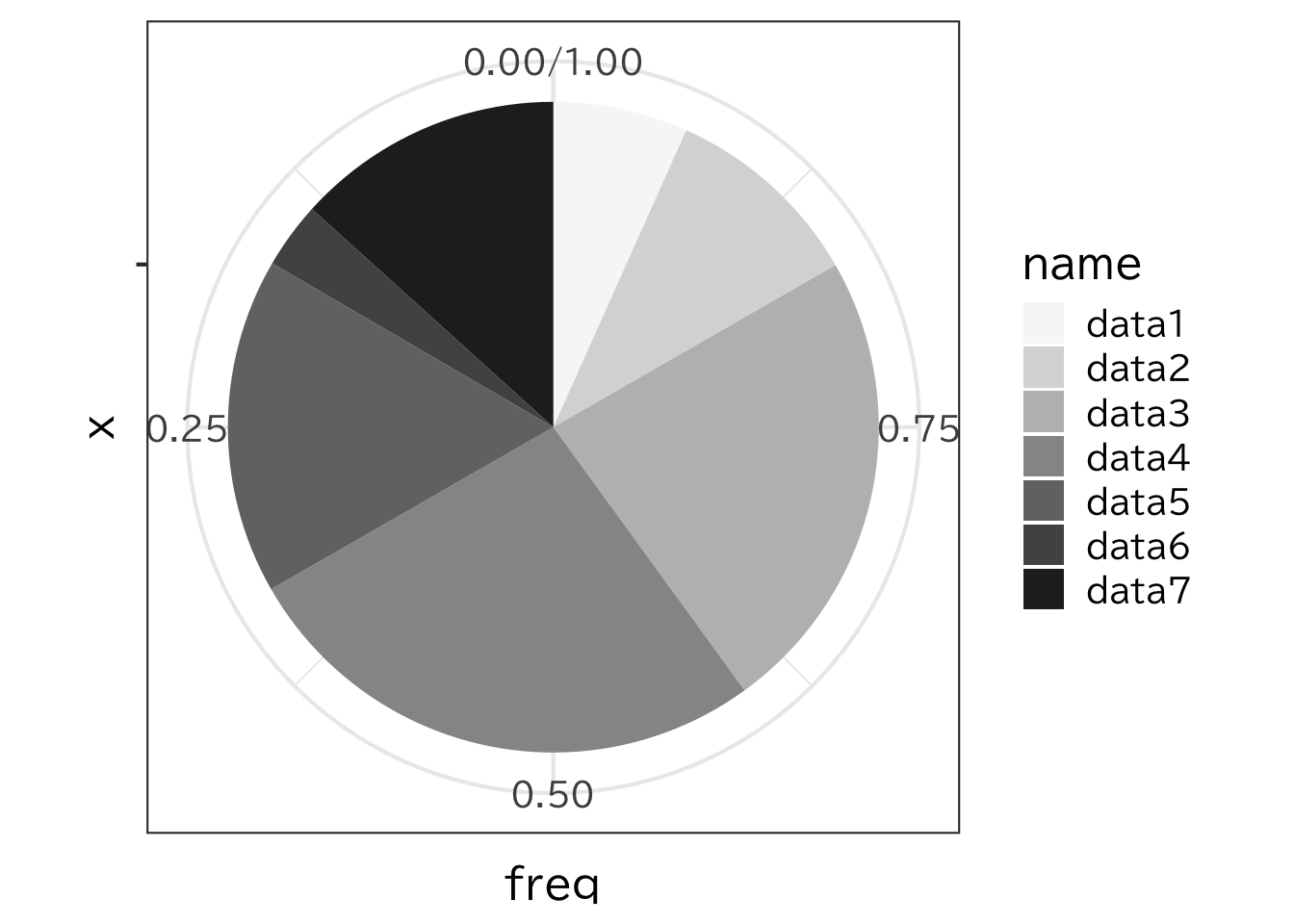
円グラフは全体の内訳を見るには向いているが、グラフから細かい値を読み取ることは難しい。 次のグラフでは図4-11の棒グラフで、それぞれの積み上げ棒の中心位置の座標を求め(pos1という列)、 そこにそれぞれの割合を表すテキストを書き、円グラフにしたものである。
> ggplot(c1,aes(x=""))+
+ geom_bar(aes(y=freq,fill=name),
+ stat="identity",position="fill")+
+ geom_text(aes(label=freq,y=pos1))+
+ coord_polar("y", direction=-1) +
+ scale_fill_brewer(palette = "Greys") 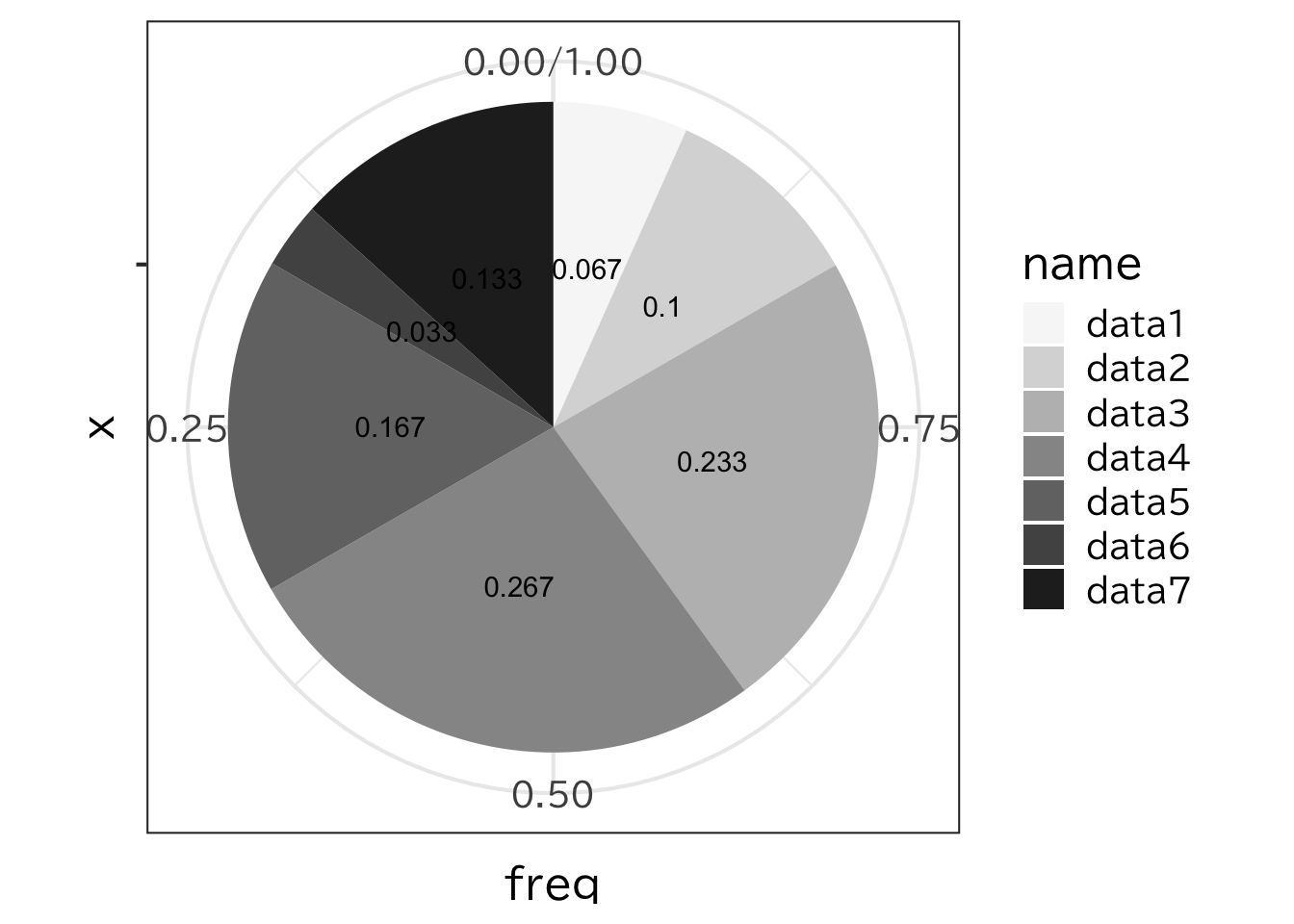
4.6 関数の描画
今までファイルからデータを読み込みそのデータを元にグラフを描画した。しかし、関数などを描画したいということもあるだろう。 その場合には以下のように新しく関数を定義してplot を使って書くことができる。
> ggplot(data = data.frame(x=c(0,2*pi) ) ,aes(x) ) +
+ geom_function(fun=sin)
以下のようにdata.frame()を省略して、xlim() で範囲を指定することもできる。
> ggplot() + xlim(0, 2*pi ) +
+ geom_function( fun=sin)
コンソールで作成したグラフは右下の小窓の Plots タブに表示される。このタブにある Export をクリックするとファイルを 保存できる。
また、ggsave()という関数もあり、幅や高さを指定してる 保存することができる。単位unitsとしてはインチin、 センチメートル cm、ミリメートル mm,画素(ピクセル)px がある。スクリプトで作成する場合にはこの方法も有効だろう。
p1 <- ggplot() +
geom_function( data = data.frame(x=c(0,2*pi) ) ,
aes(x), fun=sin)
ggsave(file="sin0.png",plot=p1,
width=5, height=3,units="cm")4.7 まとめと展望
ただ幾何的に綺麗であるグラフよりも、しっかりと相手にその意図が伝わるグラフを作成するべきである。グラフを作成する手順を順番に整理すると、
データを選ぶ
グラフの種類を選ぶ
軸の範囲, 目盛を選ぶ
となる。データはデータフレームで列を変形して、グラフに指示をする。 コンピュータを用いると、3Dグラフのように見栄えのよいグラフが簡単にできるが、見栄えのよいグラフの中には見せたくないデータを隠し、伝えたいことをオーバーに見せる目的で作成されるものもあるので、注意が必要である。 また、図だけで自分の意図がすべて伝わるわけではない。 その特徴を、図だけでなく文章としてまとめておくことも大切で、Markdown は有効である。ggplot のより詳細については [1] や [2] がある。 英語であれば Web で 見ることもできる。どちらもソースが git に公開されているので実際に確認しながら学ぶことができる。
参考文献
[1]. Hadley Wickham(著),石田基広,石田和枝(訳), “グラフィックのためのR プログラミング-ggplot2 入門”,“丸善出版”,2012, https://ggplot2-book.org/
[2]. Winston Chang(著), 石井弓美子,河内崇,瀬戸山雅人(訳) “Rグラフィックスクックブック : ggplot2によるグラフ作成のレシピ集” オライリー・ジャパン,2019,https://r-graphics.org/
[3]. 松村優哉,湯谷啓明, 紀ノ定保礼,前田, 和寛, “改訂2版 RユーザのためのRStudio[実践]入門 : tidyverseによるモダンな分析フローの世界”,技術評論社,2021年
演習
グラフの作成ではオプションがどういう意味かを忘れてしまうことがある。 いくつかのオプションを取り除いた場合のグラフも作成して残しておくと よい。
累積度数について R では
cumsum()という関数がある。逆に前後の差分を計算するdiff()という関数もある。
> x <- c(1,3,6,10,15)
> cumsum(x)[1] 1 4 10 20 35> diff(x)[1] 2 3 4 5- ヒスとグラムはどちらも描画だけであったが、 実際の度数分布も知りたい場合がある。
histはplot=FALSEとすると描画しない。 度数分布ちょうど良い階級値になるように 個数を調整する。
> hist(h2$subA,plot=FALSE)$breaks
[1] 25 30 35 40 45 50 55 60 65 70 75 80
$counts
[1] 2 4 11 12 16 21 20 8 4 1 1
$density
[1] 0.004 0.008 0.022 0.024 0.032 0.042 0.040 0.016 0.008 0.002 0.002
$mids
[1] 27.5 32.5 37.5 42.5 47.5 52.5 57.5 62.5 67.5 72.5 77.5
$xname
[1] "h2$subA"
$equidist
[1] TRUE
attr(,"class")
[1] "histogram"